|
THIS DOCUMENT IS VERY OUTDATED. Most of the core concepts still apply, however, during implementation, as requirements came into better focus, the design shifted significantly. |
Queues
Import Queue
|
TODO: Describe the import queue. |
Dataset Store Queue
Message queue that is delivered messages for every change to any object in the dataset store.
These messages must be filtered down and translated into actions that can be acted on to process changes to, installations of, or deletions of datasets.
Action Queue
|
TODO: Describe the action queue. (the queue right before the project multiplexer) |
Dataset Store
Dataset Store = Minio
|
TODO: Describe the data store. |
VDI Service
API Actions
Service actions that are exposed through and executed via the HTTP API.
| Action | Type | Description |
|---|---|---|
User |
List the datasets available to the requesting user. |
|
User |
Upload a new dataset. |
|
User |
Lookup an existing dataset that is owned by or has been shared with the requesting user. |
|
User |
Update the metadata for a dataset that is owned by the requesting user. |
|
User |
Delete a dataset that is owned by the requesting user. |
|
User |
Offer to share access to a dataset with a specific target user. |
|
User |
Revoke an existing share offer for a specific target dataset and user. |
|
User |
Accept or reject a dataset share offer. |
|
User |
List shares offered to the requesting user. |
|
Admin |
Run the reconciliation process. |
|
Admin |
Run the failed install cleanup process. |
|
Admin |
Hard delete datasets that were soft deleted more than 24 hours prior. |
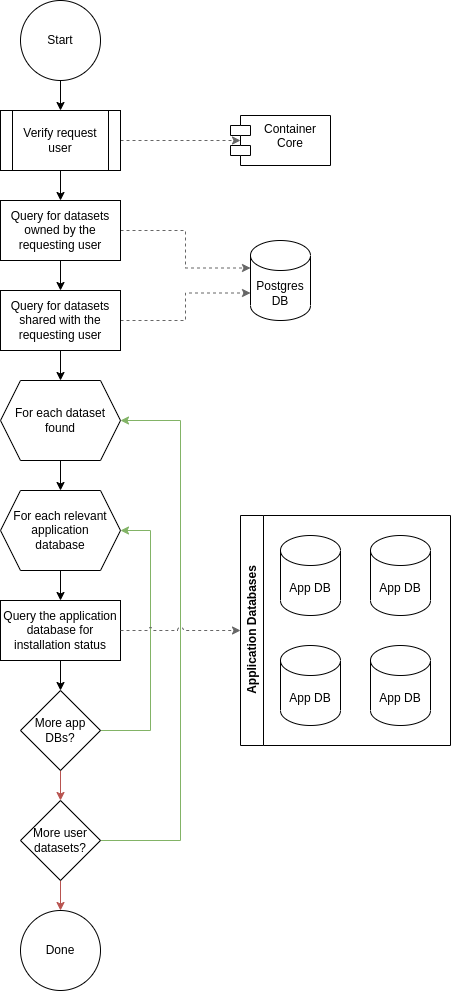
Lookup Dataset
Process Flow
-
Client makes a
GETrequest for the target user dataset -
Service validates the requesting user.
-
If the request user is invalid, return
401
-
-
Service queries postgres for information about the target dataset
-
If the dataset doesn’t exist, return
404 -
If the dataset isn’t visible to the target user, return
403 -
if the dataset has been soft deleted, return
404
-
-
Service queries application databases for installation status of dataset
-
Service returns information about the target dataset
Update Dataset Metadata
Process Flow
-
Client makes a
PATCHrequest to the user dataset containing the meta fields that should be updated. -
Service validates requesting user.
-
If the request user is invalid, return
401
-
-
Service validates request body
-
If the data in the meta fields is of the wrong type, return
400 -
If the data in the meta fields is otherwise invalid, return
422
-
-
Service queries postgres for information about the target dataset
-
If the target dataset does not exist, return
404 -
If the target dataset has been soft deleted, return
404 -
If the dataset is not owned by the requesting user, return
-
-
Service downloads the old meta JSON for the dataset from the Dataset Store
-
Service generates a new meta JSON blob for the dataset
-
Service posts the new meta JSON blob to the Dataset Store
-
Service returns a
204to the client.
Delete Dataset
Process Flow
-
Client makes a
DELETErequest to the service for a target dataset. -
Service queries postgres for information about the target dataset.
-
Service verifies the requesting user owns the target dataset.
-
Service checks the Dataset Store to ensure the dataset hasn’t been soft deleted already.
-
Shortcut to
204if it has.
-
-
Service creates a soft-delete marker object in the Dataset Store for the dataset.
-
Service returns a
204to the client.
Offer Dataset Share
|
Share offers are automatically accepted on behalf of the recipient by the service. |
|
The service sends out an email notification to the recipient notifying them of the share offer. This means that the service will need to be connected to an SMTP server. |
Q & A
What happens when a user attempts to share a dataset that failed import or installation? |
|---|
If the dataset failed import then it cannot be shared as the share action impacts the App DB, and a non-imported dataset will not have any records in the App DB. |
What about if it failed installation on some but not all of the target sites? |
We want the share to work regardless of install status, the share won’t precipitate down to the App DBs if the installation of the dataset into those App DBs has failed. |
Process Flow
-
Client makes a
PUTrequest to the service with a payload containing a share offer action ofgrant. -
Service validates the requesting user.
-
If the requesting user is invalid, return
401
-
-
Service looks up details about the target dataset in the Postgres DB
-
If the target dataset does not exist, return
404 -
If the target dataset failed import, return
403 -
If the target dataset has been soft-deleted, return
403
-
-
Service (re)places the dataset share offer in the Dataset Store.
-
Service returns
204to the client.
Revoke Dataset Share
Process Flow
-
Client makes a
PUTrequest to the service with a payload containing a share offer action ofrevoke. -
Service validates the requesting user.
-
If the requesting user is invalid, return
401
-
-
Service looks up details about the target dataset in the Postgres DB
-
If the target dataset does not exist, return a
404 -
If the target dataset has failed import, return
403 -
If the target dataset has been soft-deleted, return
403
-
-
Service (re)places the dataset share offer in the Dataset Store
-
Service returns
204to the client.
Accept/Reject Dataset Share Offer
Process Flow
-
Client makes a
PUTrequest to the service with a payload containing a share receipt action ofacceptorreject. -
Service validates the requesting user.
-
If the requesting user is invalid, return
401
-
-
Service looks up the target dataset in the postgres database.
-
If the target dataset does not exist, return
404 -
If the target dataset has been soft deleted, return
404 -
If the target dataset has no open share offer for the requesting user, return
403
-
-
If the receipt action is
accept..
Reconciliation
| TODO |
We need reconciliation to cover the (rare) case where messages get lost. This can happen if minio is up (and emitting messages) but rabbit is down so does not receive them, or… for unforeseen reasons.
The service has an admin/reconciliation endpoint, protected by admin auth.
This endpoint is automatically activated on service start up. (Caution: consider race conditions with the other campus). It can also be invoked manually by an Ops person. It is also scheduled nightly for production services.
The process is:
the reconciliation is triggered, one way or another
The service first reconciles the internal Postgres database.
The reconciler gets a listing of all files in S3, including last-modified timestamps
The reconciler iterates across those files, comparing timestamps to those in the internal DB
The reconciler synchronizes files that are out of date
After the postgres reconciliation is complete, we determine which UDs are out of sync with target appdbs.
Query MinIO to get a list of all user datasets
Query Postgres to determine which projects datasets are targeted for
Use that list of projects to segment the complete list of UDs into per-project lists
For each list, compare timestamps between minio and appdb, using a bulk operation
For each UD (if any) that are out of date, invoke the standard UD appDB synchronizer
Q & A
What happens if an exception occurs when iterating through the datasets in the Dataset Store and processing them in Postgres? |
|---|
??? |
What happens if an exception occurs when iterating through the datasets in the Dataset Store and processing them in the App DBs? |
??? |
Process Flow
-
Client makes a
POSTrequest to the admin/reconciliation endpoint. -
Service verifies the auth token in the request.
-
If the request contains no auth token, return
401 -
If the request contains an invalid auth token, return
401
-
-
Service gets a stream over the contents of the Dataset Store
-
Service groups the Dataset Store content stream into bundles of individual dataset contents
-
Service iterates through the stream of dataset bundles and:
-
Compares the timestamps of the bundle files to the timestamps recorded in the PostgresDB
-
Synchronizes files that are out of date (TODO define "synchronizes")
-
-
???
-
???
Failed Install Cleanup
There are two branches to this endpoint, the "all" branch and the "targets" branch. The "all" branch must go through and find all the failed dataset installs to process, while the "target" branch must validate that all the given dataset IDs have a broken install.
Process Flow
All Branch
-
Client makes a
POSTrequest to the admin/install-cleanup endpoint -
Service verifies the auth token in the request
-
If the request contains no auth token, return
401 -
If the request contains an invalid auth token, return
401
-
-
Service gets a list of all failed dataset installs (TODO: Define how this is done)
-
Service marks all the failed dataset installs with the
ready-for-reinstallstatus -
Service returns
204to the client.
Targets Branch
-
Client makes a
POSTrequest to the admin/install-cleanup endpoint -
Service verifies the auth token in the request
-
If the request contains no auth token, return
401 -
If the request contains an invalid auth token, return
401
-
-
Service iterates through the given list of failed dataset IDs and
-
Service looks up the target failed dataset ID in the Postgres DB
-
If the target dataset does not exist, skip to the next dataset ID
-
-
Service iterates through the list of relevant App DBs to find installation failures
-
When a failure is found, service marks the dataset with the
ready-for-reinstallstatus.
-
-
-
Service returns
204to the client.
Internal Actions
| Action | Source | Description |
|---|---|---|
Validate and transform an uploaded dataset in preparation for installation into the target site(s) database(s). |
||
Handle a change notification from the Dataset Store, sort/transform the notice into a dataset change action and publish that action message to the [Action Queue]. |
||
??? |
||
TODO: what happens downstream of S3 after a soft delete? |
||
TODO: what happens downstream of S3 after a hard delete? |
||
TODO: what happens downstream of S3 after a metadata change? |
||
TODO: what does this look like? Are there separate actions for shares being granted/revoked/accepted/rejected? |
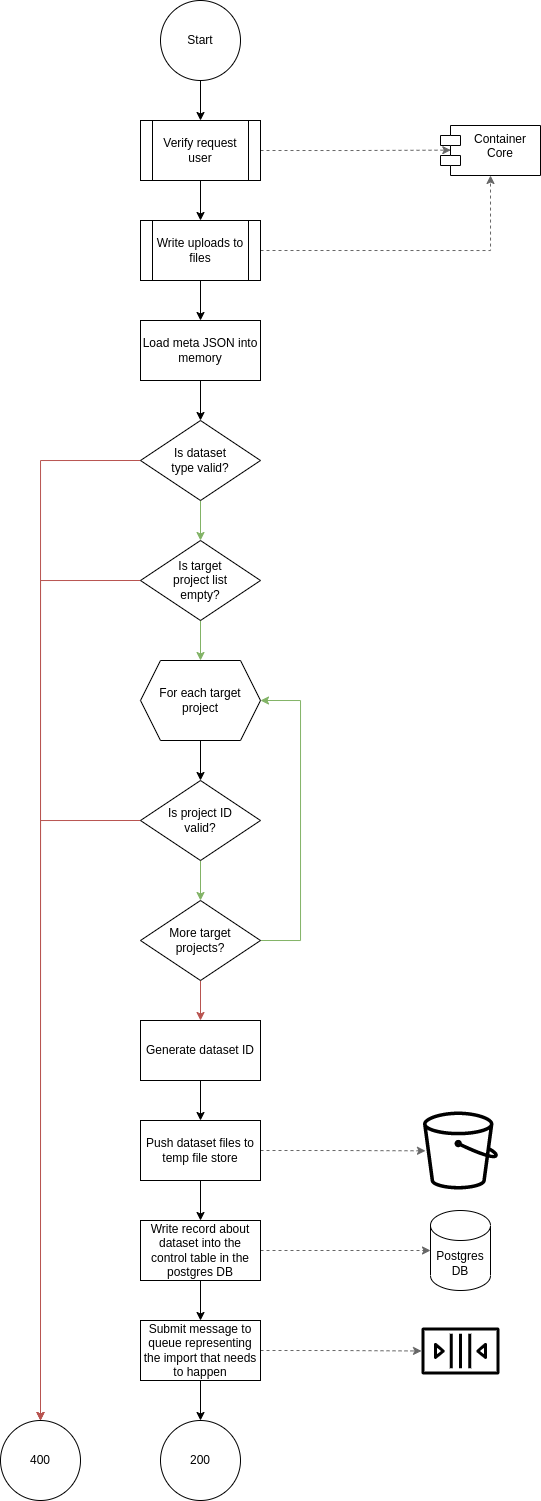
Import Dataset
Process Flow
|
TODO: the flowchart below is outdated and needs to be replaced. |
Sort Dataset Store Change
| TODO |
Dataset Installation
| TODO |
Dataset Soft Delete
| TODO |
Dataset Hard Delete
| TODO |
[OLD] Actions
|
This section is being split into the 2 sections above: API Actions and Internal Actions |
| Action | Source | Description |
|---|---|---|
RabbitMQ <2> |
Process a change in the User Dataset Store that has been published to RabbitMQ. |
|
Project Sync |
RabbitMQ <3> |
??? |
Process User Dataset Store Change
-
Determine the nature of the change ???
-
What are the possible changes that could happen?
-
marked as deleted
-
actually deleted?
-
share granted
-
share accepted
-
share rejected
-
share revoked
-
initial upload
-
meta changed
-
-
Compare the last modified timestamps in S3 to the timestamps in the postgres
sync_controltable.
-
-
???
-
Update postgres?
-
Queue changes to relevant application databases?
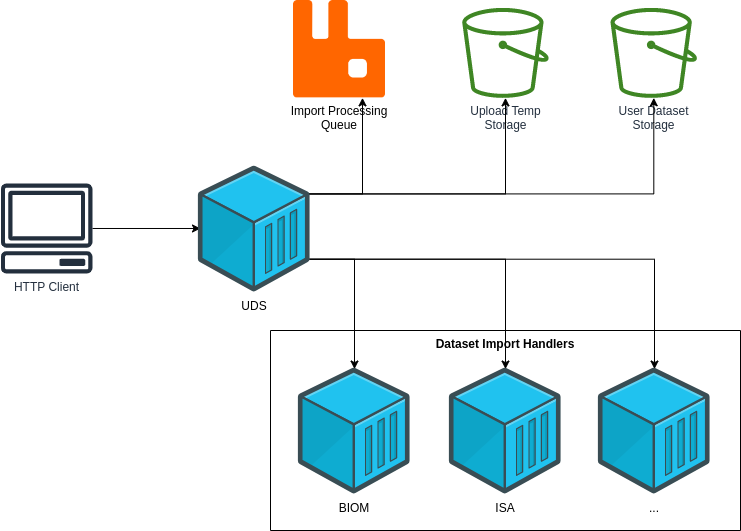
Import Handler Service
Actions
| Action | Source | Description |
|---|---|---|
HTTP |
Performs import validation/transformations on an uploaded dataset to prepare it for import and eventual installation into one or more VEuPathDB sites. |
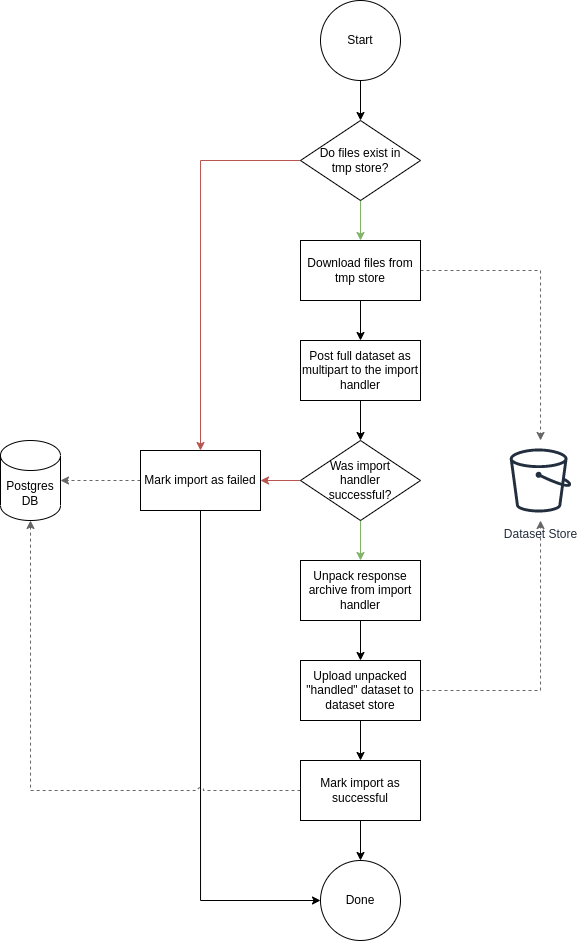
Process Import
Performs import validation/transformations on an uploaded dataset to prepare it for import and eventual installation into one or more VEuPathDB sites.
|
-
Create workspace directory for the import being processed
-
Create "input" subdirectory
-
Create "output" subdirectory
-
-
Push the files uploaded for the dataset to the "input" subdirectory of the import workspace
-
Call the import script, passing in the paths to the input and output directories
-
Generate a
vdi-manifest.jsonfile -
Generate a
vdi-meta.jsonfile -
Bundle the files placed in the output directory
-
Return the bundled archive to the HTTP caller
General Q & A
Who generates the |
|---|
The Original Design
New Design
If necessary, the input file names can be maintained as a separate array which would give us the information without implicitly enforcing any rules on input to output mapping. Optional Input Names
|
How is the user quota measured and managed? |
|---|
??? |
What if the communication between the service and the import plugin was handled via a RabbitMQ queue? |
|---|
This adds a lot of complexity to the design. If we had a stream management platform such as Apache Spark or Kafka, this would be more feasible, but without such a platform it would be difficult to test and maintain. |
Why not write the whole thing as a stream system in Spark or Kafka? |
|---|
How do we hide endpoints from the public API? |
|---|
We don’t. The endpoints will be publicly available, but will be secured with an API token |
How are the statuses displayed to the client/user? We have multiple status types; it could be confusing. |
|---|
The statuses will be returned in a "status object" as described in the misc notes below. |
| Installers: What are the inputs and outputs? |
|---|
Installers will have their data posted to them the same as with the import handler. A bulk HTTP request containing the dataset files and metadata will be submitted to the Installer Service and the installer will take it from there. |
Why is it a 2 request process to create a user dataset upload? |
|---|
We can ditch the 2-step process. Now that we have lib-jersey-multipart-jackson-pojo we don’t need to separate the meta upload from the file uploads as all the uploaded data will be preloaded into files for us automatically. |
What does the dataset delete flow look like? |
|---|
|
How are full deletes handled? We make a soft delete flag but what happens after that and who takes care of it? |
How do installers surface warnings? |
|---|
STDOUT log output from the process is gathered and posted to S3. If the installation succeeded, then these messages are considered warnings. If the installation failed, then the last of these messages is considered an error. |
How does undeleting work? |
|---|
Are the handler servers per type & database or just per type? |
|---|
Just per type, each handler will connect to multiple databases. |
How are the credentials passed to the handler server? |
A mounted JSON configuration file that will contain the credentials in a
mapping of objects keyed on the target Project ID. |
General Implementation Notes / Thoughts
-
Service will have to check the soft delete flag before permitting any actions on a user dataset.
-
The service wrapping the installer and import handler should be written in a JVM language to make use of the existing tooling for handling multipart that we have established.
Unorganized Notes
Submitting a User Dataset
-
Client sends "prep" request with metadata about the dataset to be uploaded.
-
Service sanity checks the posted metadata to ensure that it at least could be valid.
-
Service puts the metadata into an in-memory cache with a short, configurable expiration
-
Service generates a user dataset ID
-
Service returns a user dataset ID
-
-
Client sends an upload request with the file or files comprising the user dataset.
-
Service pulls the metadata for the user dataset out of the in-memory cache.
-
Service submits the metadata and the uploaded files to an internal job queue.
-
Service returns a status indicating whether the import process has been started
-
[Internal] Processing an Import
When a worker thread becomes available to process an import, it will be pulled from the queue and the following will be executed.
-
Worker submits the metadata for the job to be processed to the import handler plugin.
-
Import handler does whatever it needs to do to prepare for processing a user dataset.
-
-
Worker submits the files for the dataset to the import handler.
-
Import handler processes user dataset and produces a gzip bundle of the dataset state to be uploaded to the Dataset Store
-
-
Worker unpacks dataset bundle
-
Worker uploads dataset files to the Dataset Store
-
Worker updates the status of the dataset to "imported" or similar
Misc Notes
Notes and thoughts to be folded into the design doc above once resolved.
S3 Structure
bucket/
|- {user-id}/
| |- {dataset-id}/
| | |- uploaded/
| | | |- user-upload.tar.gz
| | |- imported/
| | | |- data/
| | | | |- data1.csv
| | | | |- data2.csv
| | | |- share/
| | | | |- {recipient-id}/
| | | | | |- owner-state.json
| | | | | |- recipient-state.json
| | | |- vdi-manifest.json
| | | |- vdi-meta.json
| | | |- deletedStatuses
- What different statuses are there?
-
-
Upload status
-
userdatasettable status (appears to also be upload status?) -
Install status (per project) (this field will be omitted or empty until the import is completed successfully)
Status representation idea?{ "statuses": { "import": "complete", "install": [ { "projectID": "PlasmoDB", "status": "complete" } ] } }
-
Shares
Sharing datasets is done as a 2 part process, a source user offers to share a dataset with a target user, and the target user has to accept the share offer.
Both these pieces must exist for a share to be valid, an active offer, and active receipt, if either side is rejected or deleted then the share is invalidated.
In the Dataset Store a share is represented by 2 empty objects, an offer object and a receipt object. These objects are keyed on both the dataset ID and the target user ID.
Misc Diagrams
Database Schemata
Internal PostgreSQL Database
Tables here cannot be the single source of truth for information about the datasets. While this database should not be wiped, it needs to be constructable from the state of the Dataset Store.
vdi.datasets
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vdi.dataset_metadata
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
vdi.sync_control
This table indicates the last modified timestamp for the various components that comprise a user dataset.
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
Timestamp of the most recent last_modified date from the user dataset share files. |
|
|
Timestamp of the most recent last_modified date from the user dataset data files. |
|
|
Timestamp of the metadata JSON last_modified date for the user dataset. |
vdi.owner_share
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
User ID of the user the dataset was shared with |
|
|
Current status of the share |
vdi.recipient_share
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
User ID of the user the dataset was shared with |
|
|
Current status of the share receipt. |
vdi.dataset_control
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
"awaiting-import", "importing", "imported", "failed" |
vdi.dataset_files
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
vdi.dataset_projects
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
Application Database
|
user_datasets
|
| Column | Type | Comment |
|---|---|---|
|
|
|
|
|
Owner user ID |
|
|
Dataset type string. |
|
|
Dataset type version string. |
|
|
??? |
|
|
Soft delete flag. |
user_dataset_install_messages
|
| Column | Type | Comment |
|---|---|---|
|
|
Foreign key to |
|
??? |
|
|
??? |
|
|
|
"running", "complete", "failed", "ready-for-reinstall" |
|
|
failure message? |
user_dataset_visibility
| Column | Type | Comment |
|---|---|---|
|
|
Foreign key to |
|
|
ID of the share recipient user who should be able to see the user dataset. |
user_dataset_projects
|
| Column | Type | Comment |
|---|---|---|
|
|
Foreign key to |
|
|
Name/ID of the target site for the user dataset. |